정의 엔트로피란 무작위 사건의 결과 또는 r.v.에 대한 불확실성을 포함하는 정보의 양을 의미한다. 예를들어, 동전던지기와 육면체 주사위 던지기 결과로 비교해보면 육면체 주사위를 던지는 경우가 엔트로피가 더 크다. 즉, 엔트로피가 높을수록 불확실성이 커지게 된다. 이와 반대로 어떠한 계에서의 정보량은 불확실성의 정도이므로 불확실성이 적은 계의 정보 엔트로피는 줄어들 수 있다.
Self-information Self-information이란 확률 $p$를 가지는 사건(혹은 메세지) $A$의 정보를 의미한다. 어떤 메세지 $m$에 대한 self-information은 다음과 같이 정의된다.
식에 따라 정보량은 확률의 $log$ 값을 나타내는데, 확률은 0~1 사이의 값이므로 이를 정보량을 양수로 표현하기 위해 $(-)$를 붙여서 양수로 만들어준다.
Entropy Self-information이 하나의 메세지에 대한 자기 자신의 정보량을 의미한다면, 엔트로피란 다수의 메세지($M$)에 대한 각각의 정보량의 평균값을 의미한다. 평균값을 계산하는 방식은 $M$의 사건들이 discrete한 경우와 continuous한 경우에 따라 각각 다음과 같이 정의 된다.
개인적으로 MATLAB의 가장 큰 장점 중 하나는 강력한 그래프 출력 기능이라고 생각한다.
실제로 나를 포함한 많은 대학원생들 및 연구자들이 매트랩을 이용해서 지금 이 순간에도 이쁜 그래프를 얻기 위해 편집과 수정을 반복하고 있을 것이다.
하지만, 그럼에도 불구하고 종종 내 모니터에서 보던 이쁜 그래프는 온데간데 사라지고 저장해뒀던 그래프를 불러면 일주일 넘게 가출했다가 거지몰골로 돌아온 행색처럼 보인다. 분명히 선도 깔끔하고 마커 사이즈도 적당하고 폰트도 모든것이 완벽했는데 EPS 포맷의 그래프는 그 모든것을 부정해버리는 것 같다.
실제로 구글을 해보면 이러한 문제에 대해 호소하는 전 세계 유저들의 글을 쉽게 찾아 볼 수 있다.
그럼 도대체 왜 이런 현상이 벌어지는 거고 우리가 원하는 이쁜 그래프는 어떻게 그릴수 있고 얻을 수 있는걸까?
일단 이러한 차이가 발생하는 가장 큰 이유는 '그림의 크기를 고려하는 단위(관점)의 차이'이다.
즉, 자신의 모니터 해상도에 따른 픽셀의 수를 기준으로 그림의 크기를 조정하기 때문에 위와 같은 문제가 발생하는 것이다. 매트랩은 기본적으로 그림 파일을 출력할 때 그림의 크기를 기본적으로 A4로 지정하고 있기 때문에 figure의 크기를 A4의 물리적 사이즈에 맞춰서 설정해줘야 한다.
위에서 언급한 문제들에 대해서 정확한 원인과 해결 방법을 상세하게 설명해 둔 'AureaGenus'님의 글이 있으니 참고하면 좋을 것 같다. [링크]
나 또한 비슷한 내용으로 고민했는데 해당 글을 참고하여 원하는 사이즈와 형태의 EPS 그래프를 얻을 수 있었다.
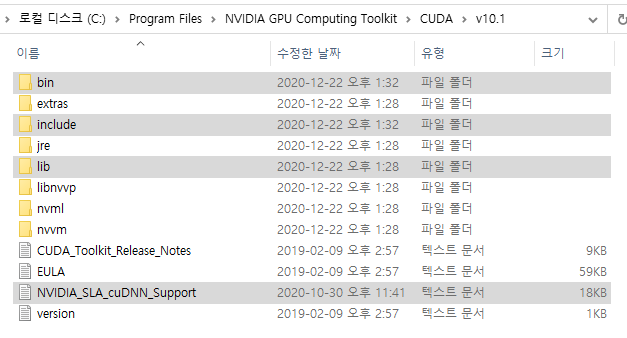
매트랩에서는 하나의 figure안에 여러개의 그래프를 그리기위해 subplot 함수를 종종 이용하는데, 문제는 subplot내의 여백이 꽤나 크다는 점이다. 따라서 subplot을 이용하여 EPS 포맷으로 그대로 저장하게 되면 각 subfigure의 그림들이 매우 작아 보이게 되어 가독성이 떨어지는 그래프가 만들어지게 된다.
아래의 코드는 subplot 2X2에 대한 예제이다.
위에서 참고한 방법과는 조금 다르게 접근한 방식인데, 전체 figure(not subplot)의 사이즈만 정해주고,
subplot들의 사이즈를 늘이거나 줄이는 방식을 통해 전체 figure의 사이즈에 딱 맞게 조절하였다.
물론 이 경우엔 약간의 노가다가 필요하지만, 그래프나 텍스트의 사이즈 및 특성에 따라 자유롭게 조절이 가능하여 subplot을 EPS 포맷으로 저장할 때 원하는 사이즈에 맞춰서 저장할 수 있다.
- 사전 자료형의 키(key)는 튜플과 마찬가지로 변경불가능(immutable)하며, 유일한 값(unique)을 가지며 값(value)은 리스트처럼 변경이 가능(mutable)하다. - 사전형은 키를 Hash table type으로 만들어 놓고 있으며, 키를 사용하여 값을 매우 빠른 속도로 찾을 수 있는 효율적이고 빠른 자료형이다.
이러한 각기 다른 자료형을 가진 변수들을 확인하는 방법은 매우 간단하다. 단순히 자료형 타입을 확인하고자 한다면 다음과 같이 print() 함수와 type() 함수를 이용하면 된다.
ElectroSense Network는 스펙트럼 데이터를 수집하고 분석하기 위한 크라우드 소싱 이니셔티브입니다.
라즈베리파이와 RTL-SDR 하드웨어로 구성된 소형 무선 센서를 사용하며, 파이썬 기반의 개방형 API를 통해 수집 된 스펙트럼 정보를 제공합니다. 이 프로젝트의 목표는 전세계 인구 밀집 지역의 스펙트럼을 감지하고 실제 스펙트럼 사용에 대한 정보를 다양한 형태로 제공하여 이를 필요로 하는 사용자들이 실시간으로 데이터를 사용할 수 있도록 하는 것이라고 한다.
해당 프로젝트에 센서 호스트로서 참여하게 되면 무료로 하드웨어를 제공받을 수 있으며 본인의 센서를 통하여 스펙트럼 센싱 및 다양한 스펙트럼 정보를 얻을 수 있다. 다만, 센서 호스트를 신청할 때에는 본 프로젝트 및 센서를 이용하여 본인이 무엇을 하려고 하는지에 대한 명확한 목표 및 정보를 제공해야 한다. 그렇지 않을경우 소리소문 없이 호스트 신청이 reject될 수 있다.
설치 및 셋팅 과정 > https://electrosense.org회원 가입 및 sensor host 신청 > application은 바로 접수되나 일반적으로 4주에 한번씩 모아서 host 선택 및 배송이 진행 > application 작성 시 목적을 적는 란이 있는데목적 및 내용을 최대한 자세하고 구체적으로 작성해야지 반려가 안됨 > 센서 호스트 승인 후 센서를 배달받을 주소지 컨펌 메일이 오며 해당 메일을 받으면 배달받을 주소를 확인한 후 이상이 없다는 답장 메일을 보내야 함
센서 조립 및 셋팅 2.1 조립 > 센서는 독일에서 해외 배송되어 오기 때문에 한국에서 수령시 꽤 오래 걸릴 수 있음 > 구성품: 라즈베리파이3 + 이미지 SD카드 + 안테나 + RTL-SDR3 silver + 라즈베리파이 케이스 + 케이블 > 조립은 가이드북(?)에 따라서 진행하면 쉽게 진행할 수 있습니다.
2.2. 소프트웨어 셋팅 및 라즈베리파이 MAC address > 기본적으로 이미지 SD 카드가 달려 있기 때문에 그냥 꼽기만 하면 됩니다. 다만 나중에 홈페이지에 자신의 센서를 등록하기 위해서는 라즈베리파이의 MAC address가 필요합니다. > 가이드 북에는 MAC address를 알아낼 수 있는 두가지 방법을 안내하고 있는데 그 중 첫 번째 방법은 SD 카드에 내부에net_info.txt 파일을 확인하는 방법이고, 두 번째는 WireShark (S/W)를 이용해서 확인하는 방법입니다. > WireShark는 다음의 [링크] 에서 다운받을 수 있습니다. 라즈베리파이와 컴퓨터를 이더넷 케이블로 다이렉트로 연결한 뒤에 WireShark를 실행 시킨 뒤 ARP (주소 결정 프로토콜, Address Resolution Protocol)를 이용해서 라즈베리파이의 MAC Address를 찾을 수 있습니다. > WireShark를 실행하면 프로토콜 간에 여러 메세지가 오고 가는데 그 중 우리가 관심있는건 라즈베리파이와의 ARP이며, 라즈베리파이의 MAC address는 일반적으로 eth.addr[0:3] == B8:27:EB로 시작하기 때문에 해당 내용으로 필터링을 하면 됩니다. [참조링크] > 라즈베리파이의 MAC address를 가지고 홈페이지에서 등록하면 됩니다.
센서 등록 및 확인 >2.까지 진행했다면 홈페이지에서 로그인 후 등록된 자신의 센서를 확인할 수 있습니다. > 센서는 등록 후 내부적으로 펌웨어 업데이트를 진행한 후 (약 15분이라고 적혀 있으나 더 걸리는 것 같음) 센서의status가 ready에서 sensing으로 바뀌게 됩니다. > 이후는 센서가 자동으로 스펙트럼 센싱한 데이터를 서버로 전송하게 됩니다.
센서 사용방법 > Electrosense 홈페이지에 사용자가 사용할 수 있는 Open API가 제공되어 있습니다. > 깃허브에 가면 API를 이용한 example들이 있으며 이를 토대로 사용자의 목적에 맞게 API를 이용해서 파이썬을 이용해서 코딩 하면 됩니다. > 현재(2020.01.23)기준으로 모든 API example은 파이썬2 에서 동작하며 파이썬3 에서는 syntax error가 발생할 수 있으므로 파이썬2로 돌리는 걸 추천합니다. > API를 이용해서 얻을 수 있는 데이터는 다음과 같습니다 - Sensor Map, Country spectrum usage, Waterfall graph, FFT data
Electrosense 홈페이지에서는 센서 호스트에 한해서 자신의 센서를 통해서 IQ data도 얻을 수 있다고 안내하고 있으나 이를 어떻게 얻을 수 있는지에 대해서는 세부적인 정보나 API를 제공하고 있지 않다.
개요 o TSN 기술은 Layer 2 (L2)의 이더넷을 기반으로 저지연(low latency)및 저지연편차(low delay variation), 저손실(low packet loss)의 확정적(deterministic) 서비스를 제공하는 기술. 네트워크 자원을 공유하는 컴포넌트 간 시간을 동기화 하고, 동기화 된 시간을 기반으로 하는 스케줄링을 통해 트래픽을 처리함으로써 장비 내에서 스위칭에 소요되는 최대 지연을 보장하는 시간 확정적 네트워크 기술.
o TSN 기술은 크게 포워딩(Forwarding) 기술, 시간 동기화 기술,경로 설정 및 자원 예약 기술, 무손실 전달(Frame Replication and Elimination for Reliability, FRER) 기술로 분류
세부 기술 1) 포워딩 기술 TSN 포워딩 기술은 기존의 브릿지(bridge) 구조 중 포워딩 프로세서와 MAC 부분에 시간 확정적 포워딩을 위한 새로운 기능을 추가함 [그림 1]. 장비 내 트래픽 전송 시간을 확정적으로 보장하지 못하는 문제를 해결하기 위해 스케줄 된 트래픽(Scheduled Traffic, 802.1Qbv) 방법은 각 트래픽 클래스 별 큐의 출력을 전송 게이트(Transmission Gate)를 통해 시간 확정적으로 제어하는 방법을 사용함
2) 시간 동기화 기술 TSN에서 시간 확정적 포워딩을 위한 시간 동기화 기술은 1588v2 PTP 기술을 사용함. [그림 2]와 같이 sync나 delay request메시지 전파 중, 중간 노드에서 큐잉 및 프로세싱에 소요되는 체류 시간(residence time)으로 인한 편차를 최소화하기 위해 E2E transparent clock 또는 peer-to-peer transparent clock 을 사용함. 1588v2는 sub-ns 수준의 시간 동기를 제공하는 프로토콜이며, sub-ns 수준으로 정밀도를 향상하기 위한 리비젼 작업을 진행 중에 있으며, 구조, 고정밀(High Accuracy), 유지보수(Upkeep), 관리, 보안 등 5개 분과로 나누어 진행 중
3) 자원 예약 기술 TSN을 위한 자원 예약 방법은 분산 모델과 부분 집중 모델(Centralized Network/Distributed User Model), 중앙 집중 모델이 존재함. - 분산 모델 경우 토커(Talker)가 전송하려는 스트림 아이디와 목적지 주소(Destination Address, DA), 가상랜(Virtual LAN, VLAN) 아이디, 트래픽 사양(Traffic Specification, TSpec)의 인자인 최대 프레임 사이즈, 최대 프레임 주기, 그리고 스트림의 우선순위, 계급(Rank)값 등을 기존의 스트림 예약 프로토콜(Stream Reservation Protocol, SRP)을 사용하여 리스너(Listener)에게 전달하여 스트림 예약을 요청하고, 리스너는 스트림 아이디를 리턴하여 등록하는 방식임. - 부분 집중 모델 토커와 리스너는 기존의 SRP 프로토콜을 통한 분산 모델과 동일하게 동작하며, 네트워크의 자원 예약은 토커와 리스너에 바로 연결된 엣지(edge) 노드에서 중앙 네트워크 설정(Centralized Network Configuration, CNC)으로 사용자/네트워크 설정 정보 (User/Network Configuration Info)라는 이름으로 전달하여 필요한 네트워크 자원을 중앙 집중형으로 예약함
4)무 손실전달 기술 TSN을 위한 저손실 기술은 기존의 브릿지 기술에서 사용되는 절체 방법이 아닌, [그림 3]과 같이 프레임 복제/삭제 방식의 무 손실전달 방법을 사용. 토커가 리스너에게 전달하는 스트림을 다중 경로로 전달 가능한 노드에서 스트림 헤더와 시퀀스 번호를 세팅하여 여러 개의 멤버 (Member) 스트림으로 복제하여 전달함. 노드에서 스트림의 중복을 체크하는 기능을 기본 복구 기능(base recovery function)이라 하며 위치에 따라 두 개의 복구 기능으로 분류됨. 입력 포트에서 중복되는 패킷을 검사하는 개별 복구 기능(Individual recovery Function)과 출력 포트에서 다중 포트로 수신된 스트림의 중복 여부를 검사하는 시퀀스 복구 기능(Sequence recovery function)이 있으며 각 복구 기능의 중복 검사는 백터 복구 알고리즘(Vector Recovery Algorithm)과 일치 복구 알고리즘(Match Recovery Algorithm) 2가지 알고리즘 중에서 선택하여 수행하게 됨.
텐서플로우는 파이썬 3.7 버전의 패키지를 제공하지 않기 때문에 아나콘다 5.3 버전을 설치할경우 파이썬을 3.6 버전으로 다운그레이드 해야 합니다. 따라서 파이썬 3.6을 사용하는 아나콘다 5.2 버전을 설치하는 것이 심신건강에 좋습니다. 아나콘다 인스톨을 마치면 시작 버튼에서 아나콘다의 설치 폴더를 확인할 수 있습니다.
2.콘다 및 파이썬 패키지 업데이트
Anaconda prompt를 실행시킨 후 콘다와 파이썬 패키지를 최신 버전으로 업데이트 합니다.
>conda update -n base conda
>conda update --all
3. Tensorflow (CPU 버전) 설치
주로 사용할 아나콘다 가상환경을 tensorflow_cpu라는 이름으로 생성 합니다.
>conda create -n tensorflow_cpu python=3.6
만들어진 tensorflow_cpu 가상환경을 activate(활성화) 합니다.
>activate tensorflow_cpu
pip를 최신버전으로 업데이트 한 후에 pip 명령어를 이용하여tensorflow(CPU버전)를 설치합니다.
>python -m pip install --upgrade pip
>pip install tensor flow
4. 파이썬 기타 라이브러리 설치
개발에 많이 사용되는 파이썬 라이브러리를 미리 설치해 놓는 것이 좋습니다.
아나콘다 콘솔에서 차트, 표, 이미지 처리 및 그래프 가시화를 위해 아래의 패키지들을 설치합니다.
매트랩에는 기본적으로 optimization toolbox가 제공되어 사용할 수 있습니다.
하지만 개인적으로 사용법이 직관적이지 않아 처음 사용하는데 애를 많이 먹었습니다.
그러던 중 전에 들었던 최적화 이론 수업 교수님이 말씀해주신 CVX tool이 생각나서 찾아서 사용해봤는데 아직까지는 매트랩에서 제공되는 optimization toolbox 보다는 훨씬 더 사용하기 편하고 직관적인 것 같습니다.
CVX guide book에 있는 소개는 간단하게 다음과 같습니다.
CVX is a modeling system for constructing and solving disciplined convex programs (DCPs). CVX supports a number of standard problem types, including linear and quadratic programs (LPs/QPs), second-order cone programs (SOCPs), and semidefinite programs (SDPs). CVX can also solve much more complex convex optimization problems, including many involving nondifferentiable functions, such as `1 norms. You can use CVX to conveniently formulate and solve constrained norm minimization, entropy maximization, determinant maximization, and many other convex programs.
As of version 2.0, CVX also solves mixed integer disciplined convex programs (MIDCPs) as well, with an appropriate integer-capable solver.
지난 2018년 6월에 2017년 Journal Citation Reports (JCR)가 발표되었습니다.
분류 항목은 Journal Impact Factor, Eigenfactor score 그리고 Article Influence score, 총 3가지로 나뉘었습니다.
- Journal Impact factor
지난 2년간 발행된(published) 저널 중 2017년에 인용된 평균 논문의 숫자 입니다.
(The average number of times articles from a journal published in the past two years have been cited in the JCR year.)
- Eigenfactor score
지난 5년간 발행된 저널 중 2017년도에 인용된 저널 및 해당
인용 저널에 기여한 저널을 고려한 횟수 입니다.
(The number of times articles from a journal published in the last five years have been cited in the JCR year while also considering which journals have contributed these citations.)
- Article Influence score
첫 발행 후 5년 동안의 평균 영향력을 결정합니다.
(The average influence of a journal’s articles over the first five years after publication.)
1. Top journals by Impact Factor
- Electrical and Electronic Engineering
Progress in Quantum Electronics
IEEE Industrial Electronics Magazine
IEEE Transactions on Pattern Analysis and Machine Intelligence
IEEE Communications Magazine
IEEE Wireless Communications Magazine
Proceedings of the IEEE
IEEE Transactions on Fuzzy Systems
IEEE Transactions on Neural Networks and Learning Systems
IEEE Signal Processing Magazine
IEEE Transactions on Smart Grid
IEEE Network
IEEE Journal on Selected Areas in Communications
IEEE Transactions on Industrial Electronics
IEEE Power Electronics
IEEE Transactions on Sustainable Energy
IEEE Transactions on Medical Imaging
Automatica
IEEE Vehicular Technology Magazine
IEEE Transactions on Wireless Communications
IEEE Internet of Things Journal
IEEE Transactions on Information Forensics and Security
IEEE Transactions on Power Systems
IEEE Journal of Emerging and Selected Topics in Power Electronics
IEEE Transaction on Image Processing
IEEE Transactions on Automatic Control
- Telecommunications
IEEE Communications Surveys and Tutorials
IEEE Communications Magazine
IEEE Wireless Communications Magazine
IEEE Network
IEEE Journal on Selected Areas in Communications
IEEE Vehicular Technology Magazine
IEEE Transactions on Wireless Communications
IEEE Internet of Things Journal
IEEE Transactions on Communications
IEEE Transactions on Vehicular Technology
IEEE Systems Journal
IEEE Transactions on Antennas and Propagation
IEEE Transactions on Mobile Computing
IEEE Transactions on Multimedia
IEEE Transactions on Broadcasting
Internet Research
Journal of Lightwave Technology
IEEE Transactions on Emerging Topics in Computing
IEEE Access
IEEE Antennas and Wireless Propagation Letters
2. Top journals by Eigenfactor score
- Electrical and Electronic Engineering
IEEE Transactions on Industrial Electronics
IEEE Transactions on Power Electronics
Automatica
IEEE Transactions on Pattern Analysis and Machine Intelligence
IEEE Transactions on Wireless Communications
IEEE Transactions on Automatic Control
IEEE Communications Magazine
IEEE Transactions on Signal Processing
IEEE Transactions on Image Processing
IEEE Transactions on Antennas and Propagation
3. Top journals by Article Influence score
- Electrical and Electronic Engineering
IEEE Transactions on Pattern Analysis and Machine Intelligence
IEEE Signal Processing Magazine
IEEE Industrial Electronics Magazine
IEEE Communications Magazine
Proceedings of the IEEE
IEEE Wireless Communications Magazine
IEEE Journal on Selected Areas in Communications
Progress in Quantum Electronics
IEEE Transactions on Neural Networks and Learning Systems
Generate random points inside a circle with radius R
이번 포스팅은 매트랩을 이용해 반지름이 R인 임의의 원을 생성하고 그 내부에 임의의 점(point)을 생성하는 방법에 대해 소개하겠습니다.
내용 및 과정 자체는 매우 심플하여 어렵지 않으나 이러한 구현은 다양한 연구분야에서 시스템 환경으로 활용됩니다. 실제로 제가 연구하고 있는 cognitive radio 시스템이나 localization에서 시뮬레이션을 위해 사용하고 있으며 이 외에 다른 여러 분야에서도 응용가능합니다.
그림 1. 반지름이 10인 원
그림 1과 같이 반지름(radius, r)이 10인 원을 먼저 그려보도록 하겠습니다. 일단 원을 그리기 위해선 기본적으로 원의 중점과 반지름을 설정해야 합니다.
%% 원 그리기
x1 = 0; % 원 중심의 x좌표
y1 = 0; % 원 중심의 y좌표
rc = 10; % 원의 반지름
[x,y] = cylinder(rc,200); % z축의 파라미터를 입력할 경우 3차원의 원통형이 생성되지만 여기서는 % 2차원의 원만 표기하기 위해 z축 파라미터는 사용하지 않습니다.
% 총 200개의 요소로 이루어진 원의 바운더리 좌표가 x, y에 각각 저장
figure(1)
plot(x(1,:)+x1, y(1,:)+y1, 'b', 'LineWidth', 2), hold on, grid on;
%앞에서 설정한 원의 중심값을 각 x, y좌표에 더해줌으로써 (x1,y1)을 중점으로 하는 반지름 10인 원을 그려주게 됩니다.'
title(['\fontsize{15}Radius=',num2str(rc)]);
xlabel('[m]'), ylabel('[m]');
코드 1. 반지름이 rc인 원 생성하기
위 코드대로 입력하시면 그림 1과 동일한 원을 그리실 수 있습니다.
그러면 이제 그 원 안에 임의의 점(point)를 생성해보도록 하겠습니다.
먼저 해당 코드를 짜기 전에 간단하게 어떤 방식으로 임의의 점을 생성시킬지 생각해봅시다.
1) 원의 중심을 기준으로 가장 멀리 떨어진 점의 거리(길이)를 반지름 이하가 되도록 한다.
-> rc값 이하의 임의의 숫자를 생성( r = rc*sqrt(rand) )
2) 원의 중심을 기준으로 임의의 라디안을 생성한다.
-> gen_rad = 2*pi*rand;
3) 1)과 2)에서 생성한 값을 이용해 원의 중점(x1, y1)으로부터 임의의 위치에 point를 생성한다.
-> x = r*cos(a)+x1, y = r*sin(a)+y1;
그러면 위에서 설명하 내용을 바탕으로 코딩을 진행해보도록 하죠.
%% 반지름이 rc인 원 생성
x1 = 0; % 원 중심의 x좌표
y1 = 0; % 원 중심의 y좌표
rc = 10; % 원의 반지름
[x,y] = cylinder(rc,200); % z축의 파라미터를 입력할 경우 3차원의 원통형이 생성되지만 여기서는 % 2차원의 원만 표기하기 위해 z축 파라미터는 사용하지 않습니다.
% 총 200개의 요소로 이루어진 원의 바운더리 좌표가 x, y에 각각 저장
figure(1)
plot(x(1,:)+x1, y(1,:)+y1, 'b', 'LineWidth', 2), hold on, grid on;
%앞에서 설정한 원의 중심값을 각 x, y좌표에 더해줌으로써 (x1,y1)을 중점으로 하는 반지름 10인 원을 그려주게 됩니다.'
title(['\fontsize{15}Radius=',num2str(rc)]);
xlabel('[m]'), ylabel('[m]');
%% 임의의 점 생성
a = 2*pi*rand( 1, length(x) );
r = sqrt( rand( 1, length(x) ) );
x11 = rc.*r.*cos(a) + x1;
y11 = rc.*r.*sin(a) + y1;
plot(x11, y11, '.r')
코드 2. 반지름이 rc인 원 생성 후 내부에 임의의 점 생성
코드 2와 같이 코드 1의 뒤에 해당 부분을 추가해주면 모든 코딩이 끝나고 그림 2와 같이 나타나게 됩니다.
그림 2. 반지름이 rc인 원 내부에 임의의 포인트 생성
또한 여기서 생성하는 임의의 포인트 숫자를 줄이거나 늘릴 수 있는데요, 코드 2부분에서 변수 a와 r의 길이를 생성할때 length(x)로 정의 했기 때문에 코드 1에서 생성한 원 바운더리의 포인트 갯수 (201개)와 동일하게 생성했습니다. 따라서, 임의의 점 개수를 늘리고 싶으시다면 해당 부분의 숫자를 조절해주시면 됩니다.
다음번 포스팅은 위 예제를 이용한 푸아송 점 과정(Poisson point process) 예제를 진행해보도록 할게요 : )
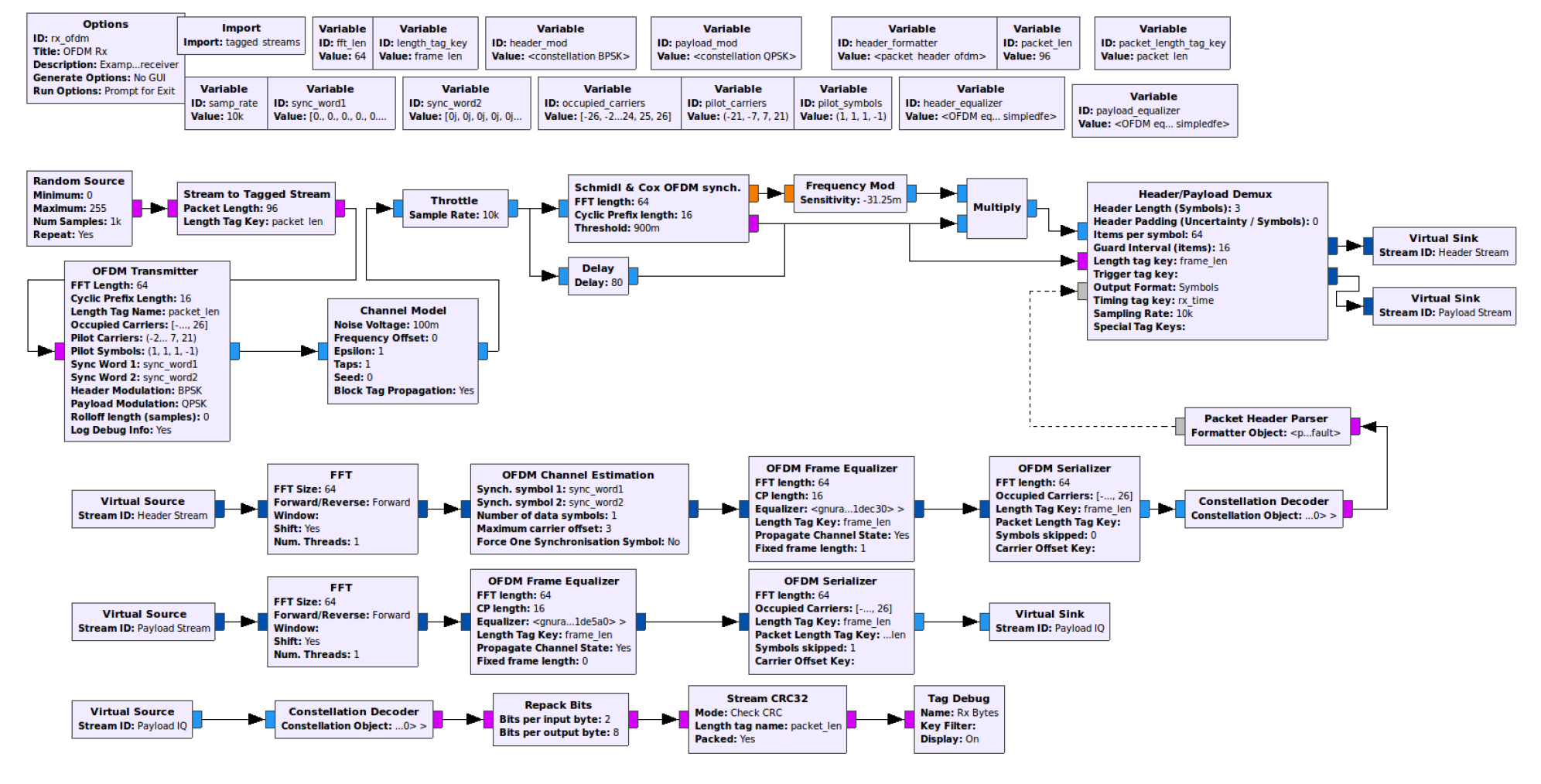
Transmitting NTSC-M video with GNU Radio and USRP 2920
이전 포스팅에서 소개했듯이 GNU Radio는 사용자의 목적과 니즈에 따라 다양한 시스템을 구현할 수 있으며 USRP를 함께 이용해 실제 무선환경에서 자신이 구축한 시스템의 통신 성능을 확인할 수 있다.
실제로 이와같이 GNU Radio와 USRP 혹은 HackRF One 과 같은 다양한 RF 장비를 이용해 실제 무선통신시스템을 구축하고 그 성능을 확인, 분석하는 예제나 데모 영상들은 구글이나 유튜브에서 쉽게 찾아볼 수 있다. 이러한 예제 중 사용자가 가장 효과적으로 그 시스템의 구현도나 성능을 쉽게 확인하기 위한 방법 중 하나는 데이터의 시각화이다.
따라서 단순한 랜덤 비트시퀀스(bit sequence)가 아닌 텍스트나 사진 혹은 영상과 같은 정형 데이터를 이용하는것이 구현 시스템의 데모를 위해 매우 효과적이라고 생각한다.
하지만 실제로 GNU Radio를 이용해 사진, 텍스트 및 영상과 같은 데이터 송수신이 가능한 시스템을 구현한 예제는 그리 많지 않으며, 그 중 실제 무선환경에서 RF 장비를 이용해 데이터를 실제로 송수신한 시스템은 더더욱 적다.
게다가 대부분의 예제는 일반 사용자들이 보고 참고할 수 있는 설명이 매우 적거나, 제한적인 정보 공개로 사용자들로 하여금 입맛만 다시고 뒤로가기 버튼을 누를 수 밖에 없는 경우도 많다.
실제 본인도 '비디오 송수신'을 위해 GNU Radio를 기반으로 시스템을 만들려고 '정말 괜찮은' 자료를 찾기위해 매우 오랜시간, 매우 다양한 예제와 데모영상을 찾아야만 했다. 그래서 분명 어딘가에 나와 같이 비슷한 고민을 갖고 이러한 자료를 찾고 있을 누군가를 위해 실제로 구현하고 성공했던 예제를 총 두개의 예제(NTSC-M 방식 / OFDM 방식)로 나누어 포스팅하려고 한다.
Part. 1
1. 개요
NTSC-M 이라는 단어는 비디오, 방송 분야쪽에 관심이 있는 사람이 아니라면 생소한 단어인데, 사실상 꽤 오랜시간동안 우리의 생활에 밀접했던 기술용어이다. 아시다시피 우리나라는 2012년 중반부터 아날로그 TV 서비스를 종료하고 DTV 서비스로 전환하였는데, 이때 아날로그 TV 서비스를 위해 사용되었던 표준이 바로 NTSC-M 방식이다.
여기서 굳이 NTSC를 장황하게 설명하는지 궁금해하는 분들도 있을텐데 비디오 송수신 시스템을 구현하는 과정에서 나와 같은 착오와 실수를 똑같이 하지 않길 바래서이다. 그럼 내가 했던 착오와 실수가 무었이 있었는지 간단히 적어보겠다.
(1) 비디오데이터도 결국엔 binary로 이루어져있을테니, 그 binary 파일만 제대로 송수신 된다면 비디오 영상 송수신도 제대로 될것이다.
ex) 동영상 파일 -> binary file -> 송수신 -> binary file -> 동영상 파일 -> 재생 -> 끝 !
(2) 결국 내가 구현하고 싶은건 (1)번의 송수신 파트이지 그 전후 단계는 GNU Radio에서 알아서 해줄테니 신경쓸 필요가 없다. 하지만 실제로 구현해보니 '송수신' 파트 뿐만 아니라 그 전후의 모든 단계도 내가 알고 있어야하고 사용하고자 하는 표준의 방식과 형태를 알아야 가능했다.
즉, 어떠한 시스템을 이용해 비디오를 재생 혹은 스트리밍할지 정확히 알아야 하며 그에 맞춰 시스템을 디자인해야 한다.
2. NTSC-M
NTSC-M 방식은 앞서 말한바와 같이 아날로그 TV의 표준(PAL, NTSC)중 하나이며, 기존의 6MHz 주파수 대역내에 컬러신호를 수용하기 위한 방식이다. (북미와 우리나라에서 채택, 유럽은 PAL 방식)
GNU Radio에서 여러 변수값들은 다음의 NTSC-M 스펙에 따라 정해지게 된다.
NTSC-M specification
Bandwidth
6MHz
Frame size
30fps(=frames/second), technically accurate 29.96 fps
표 1의 NTSC-M 표준의 스펙트럼 구성은 그림 1과 같다. Video carrier frequency(반송파)는 Channel lower boundary + 1.25MHz 라고 정의되어 있는데 이는 그림 1과 같이 각 채널의 시작 주파수에서 1.25MHz 떨어진 곳을 의미한다. 여기서 채널은 실제로 TV의 채널번호를 의미하는데 우리나라의 채널 주파수 할당은 미국의 채널 주파수 할당과 동일하며 표 2와 같다.
채널번호
주파수 대역
(a~b MHz)
영상 반송파(V)
(Video carrier freq.)
음성 반송파
(Audio carrier freq.)
2
54~60
a+1.25 = 55.25[MHz]
V+4.5 = 59.75[MHz]
3
60~66
a+1.25
V+4.5
6
82~88
''
''
14
470~476
''
''
표 2. 대한민국 아날로그 TV 주파수 할당표
3. Data conversion
NTSC-M 방식을 이용해 비디오 스트리밍을 하기 위해서는 표준에 맞게 그 형태를 바꾸어야 한다.
본인은 .mp4을 이용해 NTSC 방식에 맞도록 그림 2와 같이 데이터를 변환 및 인코딩 하였다.
그림 2. 데이터 변환 및 인코딩
앞서 NTSC-M 방식에 대해 설명한것 처럼 비디오와 오디오는 서로 다른 변조방식을 이용해서 전송되기 때문에 하나의 비디오에서 영상과 음성을 따로 분리시켜 전송해야 한다.
따라서 비디오파일을 NTSC 방식의 영상표준(30fps)에 맞춰 프레임을 캡처해 각각의 이미지 파일로 저장해야 하고 ntsc-encoder(ntsc-encode-vid-mod.py)를 이용해 .dat 형식으로 변형해줘야 한다. 마찬가지로 음성 파일도 해당 영상 파일에서 .wav 파일 형태로 추출해야 한다.
다음 포스팅에서 grc 플로우차트와 함께 각 변수에 대한 자세한 설명과 변수 값 설정을 통해 NTSC-M 송신 시스템 구현을 마무리 하도록 하겠다.
이번 포스팅은 SDR(Software Defined Radios) 시스템을 구현하는데 많이 사용되는 GNU Radio를 윈도우에 설치하는 방법을 소개하려고 합니다.
기본적으로 GNU Radio는 추가적인 RF H/W가 없어도 그 자체만으로 내부에서 다양한 통신(유무선) 환경을 구축하여 다양한 기능을 시뮬레이션 할 수 있습니다. 더욱이 추가적인 RF 장비를 함께 이용할경우 실제 유무선환경에서 자신이 구축한 시스템의 성능 평가 및 분석이 가능합니다.
이밖에 GNU Radio와 비슷한 기능을 하는 다양한 S/W가 있지만 이 쪽 분야에선 GNU Radio가 선두(?)주자로 시작하였으며 더욱이 free & open-source S/W다 보니 그 사용자 수도 많고 관련 커뮤니티의 활동 및 자료가 많은 것 같습니다.
하지만 기본적으로 Linux 기반의 소프트웨어여서 그런지 접할 기회가 없었던 분들도 많고 실제로 많은 유저들이 윈도우 OS에 익숙해서 리눅스 기반의 소프트웨어를 새로 배우고 익히는데 조금은 걱정되는 면도 존재하는 것 같습니다. 물론 저 또한 연구 목적으로 GNU Radio를 사용하기 위해 불가피하게 리눅스를 접하고 사용하였지만 그 과정이 역시나 순탄치 않았던것 같습니다.
이러한 점을 보완하기 위해서 릴리즈 된건지는 모르겠지만 어쨌든 다행히 GNU Radio를 윈도우에도 설치할 수 있으며 리눅스에서 제공되는 다양한 기능들을 사용할 수 있게끔 지속적으로 업데이트 및 배포 하고 있습니다.
2번 링크는 윈도우 기반의 바이너리 설치파일을 다운받을 수 있으며 현재(18.08.24) 3.7.12 버전까지 배포되었습니다. 해당 링크를 통해 들어가 자신의 OS 버전과 CPU에 맞춰서 다운로드를 하면 됩니다.
또한 해당 페이지에서는 기타 추가적인 GNU Radio dependencies binary 파일들도 다운받을 수 있습니다.
설치하는 과정에서는 특별히 설정해야할 부분은 없으니 편하게 설치하시면 됩니다.
기본 설치경로는 다음과 같습니다. C:\Program Files\GNURadio-3.7
2. GNURadio Companion & Command Prompt
그림 1
설치가 끝나면 그림 1과 같이 두개의 아이콘을 확인할 수 있는데, 왼쪽 아이콘은 .grc 파일을 열고 편집할 수 있는 실행파일이며, 오른쪽 아이콘은 커맨드라인을 이용해 사용할 수 있는 프롬프트 입니다.
아무래도 리눅스 기반의 소프트웨어여서 커맨드가 많기 때문에 윈도우에서도 커맨드를 사용해야 할 상황이 많습니다.
커맨드 프롬프트를 실행시키면 윈도우 커맨드 창이 뜨는데 이때 디폴트 경로는 다음과 같이 설정되어 있습니다.
"C:\Program Files\GNURadio-3.7\bin\" 해당 경로에서 GNU Radio의 다양한 커맨드 작업을 수행하실 수 있습니다. 다만 기존의 리눅스에서 사용하던 커맨드와 조금 다른것들이 몇가지 있는데 저같은 경우에는 USRP와 연결시켜 많이 사용하기 때문에 uhd 커맨드를 종종 사용합니다.
그 중 USRP 디바이스 연결 상태 확인 및 IP를 확인하기 위해 리눅스 환경에서 uhd_find_device 라는 커맨드를 종종 사용하는데 윈도우 프롬프트에서는 뒤에 .exe가 더 붙습니다.
하지만 대부분의 커맨드는 리눅스와 비슷하기 때문에 동일하게 Tab키를 통해 자동완성 기능으로 사용하시면 편할 것 같습니다.
GNU Radio는 친절하게도 다양한 예제를 함께 제공하고 있습니다. 물론 각 예제의 디테일이나 완성도는 사용자의 니즈에 꼭 맞지는 않을 수 있습니다. 하지만 여러 예제의 수정 및 조합으로 자신이 구현하고자 하는 시스템의 베이스는 구현할 수 있으니 잘 찾아보시길 바랍니다.
GNU Radio를 사용하면서 가장 아쉬운 점은 다른 프로그램에 비해 국내 자료가 매우 부족한 점이었습니다. 물론 갓구글님과 양덕 형님들이 항상 도와주시지만 여전히 한글자료에 대한 갈증은 어쩔 수 없는 것 같습니다 ㅠㅠ
앞으로 보다 많은 국내 사용자들이 활발한 정보공유 및 활동을 통해 많은 사용자들이 도움 받을 수 있었으면 좋겠습니다.
일반적으로 수중채널은 대기중의 채널 특성에 반해 제약적인 부분도 많으며 그에 따른 특징도 다양하다.
대기중에서 RF wave는 빛의 속도에 준하는 속도로 움직이는 반면, 음파(sound)의 경우는 대략 333m/s의 속도로 RF wave와의 속도 차이가 엄청나다. 하지만 반대로 '수중'이라는 채널에서는 대기중에서의 속도와 차이가 나는데, 음파같은 경우는 대기중에서보다 수중에서의 속도가 약 5배 정도(1500m/s)증가하게 된다.
이러한 속도적인 특징이 수중 무선통신을 위해 음파를 사용하는 주된 이유이기도 하다.
그렇다면 수중채널은 어떠한 특별한 특징을 갖고 있는지에 대해서 간략하게 설명해보고자 한다.
기본적으로 바다 또한 일반 대기와 마찬가지로 분류되는 층이 존재한다. 그 중 수온에 따른 분류를 하게 되면 수중은 혼합층, 수온약층, 심해층으로 분류 할 수 있다.
1. 혼합층
- 바람의 혼합 작용에 의해 상, 하 바닷물이 혼합되면서 일정한 온도층을 형성
- 전형적인 혼합층의 수심은 150m 이지만 지역적인 조건에 따라서는 그 깊이가 1000m까지 되는 곳도 있으며 반대로 전혀 나타나 지 않는 경우도 있다. 조금더 자세히 말하면 위도에 따라 살펴보게 되면 중위도는 적도에 비해서 풍속이 크기 때문에 더 깊은 곳
까지 물이 섞이게 된다. 반대로 극지방의 경우엔 표층의 온도와 해저면의 온도가 거의 동일하기 때문에 혼합층이 심해층과 거의 같다.
2. 수온약층
- 따뜻한 혼합층과 차가운 심해층 사이에 위치하기 때문에아래로 내려갈수록 온도가 급감한다. 수온약층은 대기권의
성층권과 같이 가장 안정(밀도가 큰 찬물이 아래에 있고 밀도가 작은 따뜻한 물이 위에 있음)한 층으로 혼합층과 심해층의



































 CVX_guide book.pdf
CVX_guide book.pdf








 ntsc-encode-vid-mod.py
ntsc-encode-vid-mod.py
